The examples shown in this chapter use the Java Native Interface (JNI) mechanism to glue the Java language code and the C language code together. For more information about JNI, see The Java Native Interface: Programmer's Guide and Specification.1
This chapter starts with a substantial example of porting an algorithm written with the Java language to C. Although this is a complex numerical algorithm, of the type people are often encouraged to code in C, the performance of the C version turns out to be poor. Section 9.2 takes a more detailed look at the various costs associated with using JNI, and describes several different patterns used to write native code-some that can be fast and some that are generally slow. Section 9.3 finishes up the chapter by looking at a few case studies that highlight decisions about using native code.
public class DowncodedBresenham implements LineDrawer {
static {
try {
System.loadLibrary("bresenham");
} catch (Exception e) {
e.printStackTrace();
}
}
public native void drawLine(BufferedImage i,
int x0, int y0,
int x1, int y1);
}
Interface to the native drawing code
#include "DowncodedBresenham.h"
static jclass biclass = NULL;
static jmethodID bimid;
// macro to call pixel set on bufferedimage
#define SETRGB(bi,x,y,rgbval) \
env->CallVoidMethod(bi,bimid,x,y,rgbval)
static void octant0(JNIEnv *env,jobject bi, jint x0, jint y0,
int dx, int dy, int xdirection);
static void octant1(JNIEnv *env,jobject bi, jint x0, jint y0,
int dx, int dy, int xdirection);
JNIEXPORT void JNICALL Java_DowncodedBresenham_drawLine
(JNIEnv *env, jobject thisObj, jobject bufferedImage,
jint x0, jint y0, jint x1, jint y1){
int temp,dx,dy;
// set up class and method pointers
if (biclass == NULL) {
biclass = env->GetObjectClass(bufferedImage);
bimid = env->GetMethodID(biclass,"setRGB","(III)V");
}
// reduce to half the octant cases by always drawing + in y
if (y0>y1) {
temp = y0;
y0 = y1;
y1 = temp;
temp = x0;
x0 = x1;
x1 = temp;
}
dx = x1-x0;
dy = y1-y0;
if (dx>0) {
if (dx>dy) {
octant0(env,bufferedImage,x0,y0,dx,dy,1);
} else {
octant1(env,bufferedImage,x0,y0,dx,dy,1);
}
} else {
dx = -dx;
if (dx>dy) {
octant0(env,bufferedImage,x0,y0,dx,dy,-1);
} else {
octant1(env,bufferedImage,x0,y0,dx,dy,-1);
}
}
}
static void octant0(JNIEnv *env,jobject bi, jint x0, jint y0,
int dx, int dy, int xdirection){
int DeltaYx2;
int DeltaYx2MinusDeltaXx2;
int ErrorTerm;
jint pix = 0xffffffff;
// set up initial error term and drawing values
DeltaYx2 = dy*2;
DeltaYx2MinusDeltaXx2 = DeltaYx2 - (dx*2);
ErrorTerm = DeltaYx2 - dx;
// draw loop
//bi.setRGB(x0,y0,pix); // draws a single point
SETRGB(bi,x0,y0,pix);
while ( dx-- > 0) {
// check if we need to advance y
if (ErrorTerm >=0) {
// advance Y and reset ErrorTerm
y0++;
ErrorTerm += DeltaYx2MinusDeltaXx2;
} else {
// add error to ErrorTerm
ErrorTerm += DeltaYx2;
}
x0 += xdirection;
//bi.setRGB(x0,y0,pix);
SETRGB(bi,x0,y0,pix);
}
}
static void octant1(JNIEnv *env,jobject bi, jint x0, jint y0,
int dx, int dy,
int xdirection){
int DeltaXx2;
int DeltaXx2MinusDeltaYx2;
int ErrorTerm;
jint pix = 0xffffffff;
// set up initial error term and drawing values
DeltaXx2 = dx * 2;
DeltaXx2MinusDeltaYx2 = DeltaXx2 - (dy*2);
ErrorTerm = DeltaXx2- dy;
// draw loop
//bi.setRGB(x0,y0,pix);
SETRGB(bi,x0,y0,pix);
while ( dy-- > 0) {
// check if we need to advance x
if (ErrorTerm >= 0) {
// advance X and reset ErrorTerm
x0 += xdirection;
ErrorTerm += DeltaXx2MinusDeltaYx2;
} else {
// add to ErrorTerm
ErrorTerm += DeltaXx2;
}
y0++;
//bi.setRGB(x0,y0,pix);
SETRGB(bi,x0,y0,pix);
}
}
C implementation of LineDrawer
The relative performance of the Java language and C language versions of Bresenham's algorithm can be measured using the wrapper shown in Listing 9-3.
import java.lang.reflect.*;
public class GridApp{
public static void main(String args[]) {
if (Array.getLength(args)<1) {
System.out.println("usage: TrivialApplication b|d");
System.exit(0);
}
if ((args[0].startsWith("b"))||(args[0].startsWith("B")))
new GridTest(new BasicBreshenham());
else
new GridTest(new DowncodedBresenham());
}
}
Micro-benchmark for line drawing
The comparison of the line drawing implementations illustrates two things:
Note: The performance costs of the different JNI patterns tend to be very platform and JVM dependent. The benchmark results in this chapter are illustrative of the results you might see on a JVM implementation that supports JNI, but specific results and relative costs might differ widely under different configurations.
Listing 9-4 shows several examples of the different JNI patterns. These examples help illustrate some of the costs associated with accessing native code.
public class TrivialApplication {
static {
try {
System.loadLibrary("copytest");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String args[]) {
long time;
int[] intarray = new int[1000];
int[] intarray2 = new int[1000];
Stopwatch watch = new Stopwatch().start();
for (int i=0;i<100000;i++) {
System.arraycopy(intarray,0,intarray2,0,1000);
}
time =watch.getElapsedTime();
System.out.println("arraycopy() = "+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
for (int j=0;j<1000;j++) {
intarray2[j] = intarray[j];
}
}
time = watch.getElapsedTime();
System.out.println("assign = "+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
dumbnativecopy(intarray,intarray2,1000);
}
time =watch.getElapsedTime();
System.out.println("dumbnativecopy() ="+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
nativedonothing(intarray,intarray2,1000);
}
time =watch.getElapsedTime();
System.out.println("nativedonothing() ="+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
nativedoabsolutelynothing(intarray,intarray2,1000);
}
time =watch.getElapsedTime();
System.out.println("nativedoabsolutelynothing()= "+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
nativecritical(intarray,intarray2,1000);
}
time =watch.getElapsedTime();
System.out.println("nativecritical() ="+time);
watch.reset().start();
for (int i=0;i<100000;i++) {
nativecriticalmemcpy(intarray,intarray2,1000);
}
time =watch.getElapsedTime();
System.out.println("timeusing nativecriticalmemcpy() ="+time);
watch.stop();
}
public static native void dumbnativecopy(int[] i1,
int[] i2,
int size);
public static native void lessdumbnativecopy(int[] i1,
int[] i2,
int size);
public static native void nativedonothing(int[] i1,
int[] i2,
int size);
public static native void nativedoabsolutelynothing(int[] i1,
int[] i2,
int size);
public static native void nativecritical(int[] i1,
int[] i2,
int size);
public static native void nativecriticalmemcpy(int[] i1,
int[] i2,
int size);
}
Array copy JNI test
In Listing 9-4, a number of different techniques are used to copy an array that contains 1,000 elements. The copy operations are performed using various native and nonnative methods. To make it easier to compare the performance of these different techniques, the program performs each copy 10,000 times.
The first two copy techniques don't use any native code; the rest call C functions. These C functions are written using different JNI usage patterns to illustrate the costs associated with different coding techniques. Note that some of these C functions don't perform the full array copy; they're included to highlight the costs of particular operations. Table 9-1 shows the benchmark results for the different methods.
assign method uses a simple Java language
loop to perform the copy. This isn't the fastest option, but it isn't the
slowest either. The other nonnative option is to use the
System.arraycopy method. This turns out to be the fastest way to
perform the copy. The next few sections examine why this is the case.
Call pattern

The simplest JNI pattern is the Call pattern. In this pattern, you simply call a C function, pass along primitive arguments, and expect a primitive return type. A diagram of this pattern is shown in Figure 9-1.
This pattern can be quite efficient in certain
circumstances. Listing
9-5 shows an example of this pattern, the
nativedoabsolutelynothing method.
JNIEXPORT void JNICALL
java_TrivialApplication_nativedoabsolutelynothing
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size) {
// Do nothing
}
Call example
While the nativedoabsolutelynothing method
doesn't actually do anything, there still is a cost associated with it. In our
measurements, it took 63 milliseconds to call this method 10,000 times. This
might not seem like much, but compared to the System.arraycopy
method it's a significant amount of time.
It is most appropriate to use this pattern when you have a considerable amount of work to do inside the C code. The more work you do in the C code, the less important the overhead of the JVM to C call is. However, many problems require the use of nonprimitive data (such as arrays or objects). In these cases, you can't use this pattern.
Call-Pull pattern
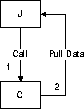
When you use the Call-Pull pattern, you call a native function that pulls a complex data type, such as an array or an object, from the JVM. This pattern is illustrated in Figure 9-2. Note that the arrows show the directions of the calls, not the direction that the data moves.
In the Call-Pull example in Listing
9-6, the method is passed pointers to the Java language array structures.
Before it can actually manipulate the contents of the arrays, however, it has to
make a local copy of the data by calling the GetIntArrayRegion
method. This method reaches back up into the JVM to copy the requested data,
which is quite expensive.
In our tests, it took almost 400 milliseconds to call this
method 10,000 times. That is much longer than the entire copy took using
arraycopy, and this method doesn't actually return a new copy of
the array. As you'll see in the next section, that takes even longer.
This extra expense is required to ensure thread safety. If you have your own copy of the data, then you don't need to worry about some other thread (such as the garbage collector) altering your data while you're working on it.
JNIEXPORT void JNICALL Java_TrivialApplication_nativepullonly
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size){
long *int1;
int1 = (long *)malloc(sizeof(long)*size);
env->GetIntArrayRegion(i1,0,size,int1);
free(int1);
}
Call-Pull example
The Call-Pull pattern can be appropriate if you have a piece of complex data and just need to return a simple result-for example, if you needed to take a block of data, perform complex statistical analysis on that data, and then return a primitive result. However, the cost of bringing down the data can outweigh any benefit you get from translating to C code. If you choose to write native code using this pattern, you need to carefully measure its performance to make sure you're getting a net benefit.
Call-Pull-Push pattern
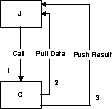
Call-Pull-Push is a common pattern in JNI code. In fact, this is the pattern that is required to actually fully accomplish an array copy operation. This pattern is illustrated in Figure 9-3.
The nativedonothing method in Listing
9-7 is the simplest example of this pattern. Like the example in Listing
9-5, the GetIntArrayRegion is used to create a local copy of
the array. This version then adds a call to SetIntArrayRegion to
push the data back to the JVM.
JNIEXPORT void JNICALL Java_TrivialApplication_nativedonothing
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size) {
long *int1;
long *int2;
int1 = (long *)malloc(sizeof(long)*size);
int2 = (long *)malloc(sizeof(long)*size);
env->GetIntArrayRegion(i1,0,size,int1);
env->SetIntArrayRegion(i2,0,size,int2);
free(int1);
free(int2);
}
nativedonothingDespite the fact that the nativedonothing
function does no useful work, it is still very time-consuming. The amount of
time consumed by this method was even greater than the very naive Java
programming language loop copy, and was several times more expensive than
System.arraycopy version.
Listing 9-8 includes the first native function that fully performs the array copy. It uses the same get and put calls as the previous example, but also adds a loop to copy the array. It is interesting to note that the version that actually copies the array is only 40 percent slower than the version that does nothing. That gives you an idea of how large the overhead of copying these arguments can be.
JNIEXPORT void JNICALL Java_TrivialApplication_dumbnativecopy
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size){
long *int1;
long *int2;
int1 = (long *)malloc(sizeof(long)*size);
int2 = (long *)malloc(sizeof(long)*size);
env->GetIntArrayRegion(i1,0,size,int1);
for (int i=0;i<size;i++) {
int2[i] = int1[i];
}
env->SetIntArrayRegion(i2,0,size,int2);
free(int1);
free(int2);
}
dumbnativecopy
JNI includes what are called critical accessor
functions. These functions give your native code direct access to data
structures inside the Java object heap, without requiring that they be copied.
This results in a substantial performance boost. An example of this pattern is
shown in Listing
9-9. To access the data, the GetPrimitiveArrayCritical method
is used.
JNIEXPORT void JNICALL Java_TrivialApplication_nativecritical
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size){
int *int1 = (int *)env->GetPrimitiveArrayCritical(i1,0);
int *int2 = (int *)env->GetPrimitiveArrayCritical(i2,0);
int count = size*sizeof(jint)/sizeof(int);
int *iptr1 = int1;
int *iptr2 = int2;
for (int i=0;i<count;i++) {
*iptr2++ = *iptr1++;
}
env->ReleasePrimitiveArrayCritical(i1,int1,0);
env->ReleasePrimitiveArrayCritical(i2,int2,0);
}
nativecriticalIn this case, using the critical methods speeds up the array copy by nearly three times. This speedup is due to the fact that the data isn't copied to local storage. But how do these critical methods maintain thread safety if the data isn't copied? The answer to this question reveals the limitations of this solution. When you use a critical method to access data inside a native method, all threads inside the JVM are blocked to maintain thread safety.
This includes not only user threads, but threads such as the garbage collector. This means that you cannot use these critical methods in a native function that might block. For example, if the method touches the file system, video memory, or any other structures that might have locks held by threads inside the JVM, then your program can deadlock. If more than a few milliseconds is spent in such a method, it's also possible to block threads, such as the user interface thread, in a manner that can make the user think the program has crashed. If you can work within these constraints, however, these methods can be a big boon to performance.
For completeness, there is one more native function to
discuss-nativecriticalmemcpy, which is shown in Listing
9-10. This is the fastest way to write the array copy functionality using
JNI. It uses the critical functions to access the data, as shown in the previous
example. However, it replaces the loop with a call to the standard C
memcpy function. This low-level call is optimized for just this
kind of work, and in fact provides a 25 percent speedup over the previous
example.
JNIEXPORT void JNICALL
Java_TrivialApplication_nativecriticalmemcpy
(JNIEnv *env, jclass myclass,
jintArray i1, jintArray i2, jint size){
int *int1 = (int *)env->GetPrimitiveArrayCritical(i1,0);
int *int2 = (int *)env->GetPrimitiveArrayCritical(i2,0);
int count = size*sizeof(jint)/sizeof(int);
int *iptr1 = int1;
int *iptr2 = int2;
memcpy(iptr2,iptr1,count*sizeof(int));
env->ReleasePrimitiveArrayCritical(i1,int1,0);
env->ReleasePrimitiveArrayCritical(i2,int2,0);
}
nativecriticalmemcopyDespite the fact that the critical methods can provide a
substantial performance boost, the fastest native version of this method is
still slower than the version that uses System.arraycopy. This is
because System.arrayCopy is designed to work with full knowledge of
the JVM's internals, and doesn't incur any of the overhead suffered by normal
JNI calls.
Call-Invoke pattern
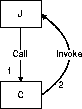
One more pattern that is commonly found in JNI code is Call-Invoke. In this pattern, the JVM calls a native method, which in turn calls one or more Java language methods. This pattern is illustrated in Figure 9-4.
The native Bresenham line drawing example shown at the beginning of this chapter uses this pattern. The line drawing native method is called, and then repeatedly calls a Java method to manipulate the pixels in the buffered image.
As you recall, the Bresenham example was substantially slower when coded in C than with the Java programming language. The Call-Invoke pattern often leads to performance problems. When you create native methods that call Java methods, you are likely to have performance problems. You generally are better off writing the code entirely in the Java programming language.
Why does the Call-Invoke pattern typically show poor results? The main reason is that invoking a Java language method from C uses a mechanism similar to the JVM reflection mechanism. Reflective method lookup and dispatch is fine for many uses, but if you're coding in C to improve performance, then the last thing you want to be doing is using reflection to invoke methods.
A cross-platform implementation of JMF that runs on any standard runtime environment is currently available. However, there are also performance packs available for the Windows and Solaris platforms that use native code for selected codecs. When downloading the JMF bundle, you can choose between the cross-platform implementation and the version with the performance pack for your platform.
java.math package.
This package contains classes for doing mathematical operations on very large
numbers and contains many complex numerical algorithms. Previous versions of
this code had been written almost entirely in C, but this made maintenance
complex, so the code was rewritten using the Java programming language. However,
it was critical that performance not suffer.
During the project it became clear that the JNI overhead for some operations was very high. Most lightweight operations became substantially faster when translated into Java code. In addition, removing the C code made the design so much cleaner that it was possible to change the implementation to use more efficient algorithms. For an example of one of these algorithmic changes see Section 7.5, Mutable Object Case Study.
When the project was completed, benchmarks showed that most operations were much faster in the Java programming language version than they were in the C version. In many cases, operations were several hundred percent faster.
If you're interested in writing high-performance software with Java 3D, see the Java 3D Performance Guide at http://java.sun.com/products/java-media/3D/collateral/j3d_perguide.html.
Sheng Liang, The Java Native Interface: Programmer's Guide and Specification. Addison-Wesley, 1999.
2Codec is an abbreviation of coder/decoder, the part of the system that compresses and decompresses media data.
Copyright © 2001, Sun Microsystems,Inc.. All rights reserved.